Hi everyone,
I’m trying to clarify the current state of active-active / multi-master support in DragonflyDB as of 2025. Information online seems a bit confusing, especially with the introduction of DragonflyDB Swarm.
Some sources suggest that Swarm is bringing clustering and replication improvements, but it’s not clear whether this includes true active-active (multi-master) capabilities, or if it’s still limited to primary-replica setups.
Does anyone know the exact status? Is active-active supported now, on the roadmap, or still not part of DragonflyDB’s design?
Thanks!
Hi @BelroDe,
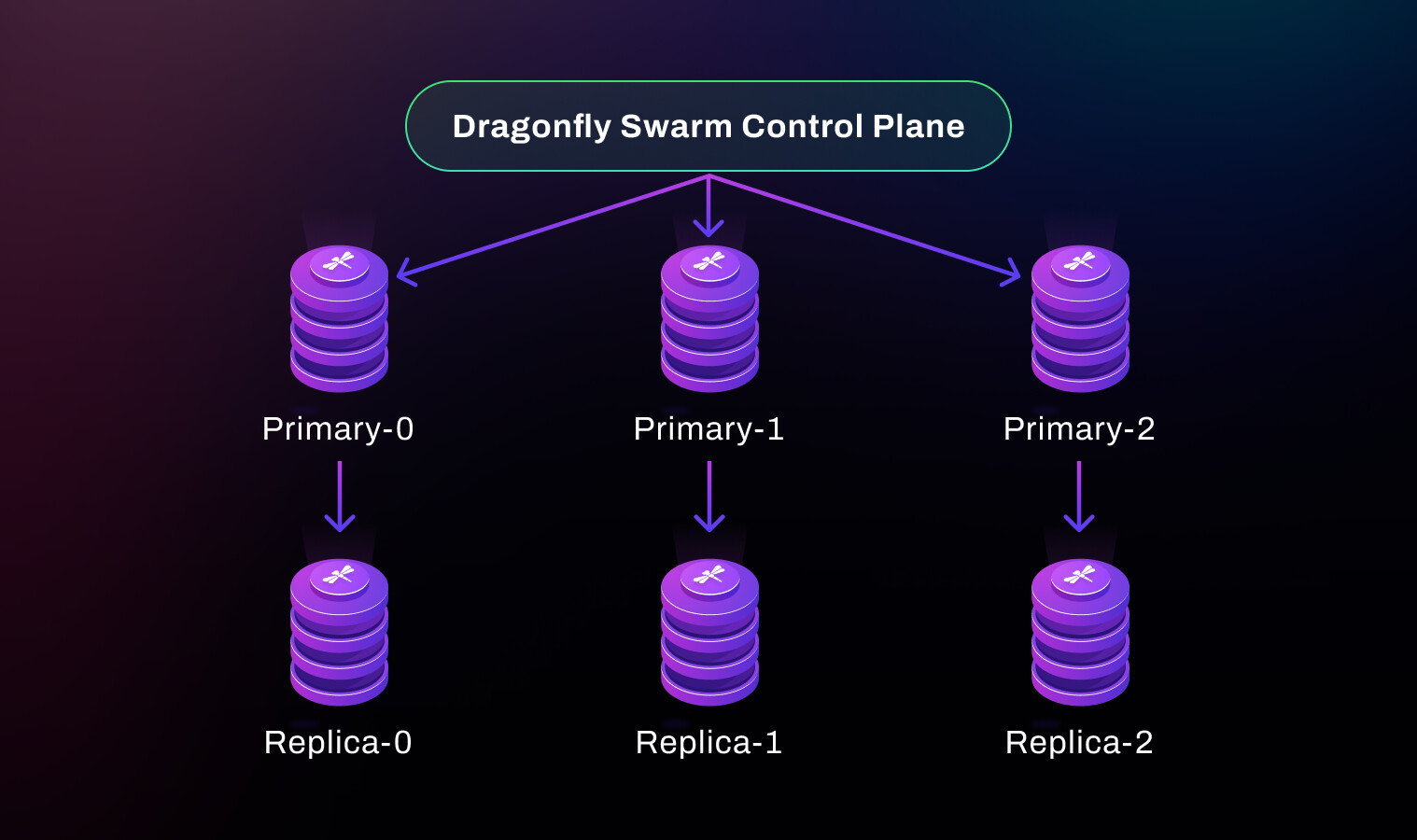
Dragonfly Swarm is our solution for horizontal scaling. It is a sharded topology with clustering. So, Dragonfly standalone scales vertically first. And if your workload is getting beyond 1TB, Dragonfly Swarm can be used to scale horizontally.
Here is an example Dragonfly Swarm topology. For example, replica-0 is there to provide high availability and optionally serve additional reads for primary-0. Data in primary-0 & replica-0 never appears in other shards. Please don’t confuse sharding with active-active, even though they both have multiple primary instances (masters).
On the other hand, in an active-active topology, a key-value pair may reside in multiple masters.
As of 2025, Dragonfly Swarm multi-shard cluster is already available in Dragonfly Cloud. But we don’t have a solid plan for active-active yet.
Okay, thank you for the clear clarification!
I’m really looking forward to seeing what you can do regarding the active-active solution.
Since you’re an expert, I’d love to hear how you would implement an active-active approach in the current context. My challenge is at the level of a rate limiter: I want to use an active-active setup to share the limit across all my backend applications (for example, my backend is distributed across multiple regions, like Germany and the US).
Currently, not replicating a user’s quota creates a risk of token rate limiting evasion — for instance, a user could hit the limit in the Germany region and then immediately make additional requests in the US region, effectively bypassing the intended limits.
As a junior dev, I’d appreciate your thoughts on the best way to handle this in an active-active configuration.
That’s not as easy as it seems. Take databases (or data stores) as an example.
Some databases rely on sophisticated strong consensus algorithms (like Raft or Paxos) to ensure strict consistency across nodes, even across regions. However, this comes at the cost of higher latency. These systems are typically on-disk databases that prioritize durability and throughput, where slightly higher latency is an acceptable tradeoff for scalability and performance.
On the other hand, some databases opt for eventual consistency, often using conflict-free replicated data types (CRDTs). These prioritize low latency and high throughput. If Dragonfly were to implement active-active replication, CRDTs could be a viable choice, but this would mean sacrificing strong immediate consistency. In such cases, a certain degree of stale reads might be acceptable.
Alternatively, you can consider just region-splitting the application (amazon.com for the US and amazon.ca for Canada). If an application is not there yet (popularity, user base, etc.), I’d suggest not complicating things.
Ultimately, it all comes down to tradeoffs, whether at the database layer or the application layer. Hope that helps.
Hi!! Thank you so much for this precious information! I will keep searching and thinking about all of that. Thanks! Wishing you the best.
1 Like